I look after quite a number of servers, many of which are different flavours of Unix and Linux. Checking disk usage is easy with the df command but I wanted to setup something automatic, where I could get a view of all the systems at once. I wanted the disk usage from every system, regardless of operating system to end up in an Excel spreadsheet for review, something like this:

Use awk to produce JSON from the df command
The df command has a “-P” option which will produce Posix style output. This ensures the output is the same regardless of the operating system generating the output. Also to ensure the size output was the same I used the -k option. So the df command I used is:
df -P -k | grep -v "/snap/core"
Which produces output like this:
Filesystem 1024-blocks Used Available Capacity Mounted on udev 1988700 0 1988700 0% /dev tmpfs 403972 1092 402880 1% /run /dev/sda2 32893712 17614104 13585656 57% / tmpfs 2019852 0 2019852 0% /dev/shm tmpfs 5120 0 5120 0% /run/lock tmpfs 2019852 0 2019852 0% /sys/fs/cgroup /dev/sdb1 263174148 61536 249690892 1% /u tmpfs 403968 0 403968 0% /run/user/1000
I wanted to remove some of the file systems from the report, so they were filtered out with grep.
Convert the output of df to JSON
Next I converted the output of the df command to JSON format using awk so that it be consumed with Microsoft Flow. I passed some variables into the awk script make it easy to identify the machine later and to generate a unique key (for Microsoft Flow):
BEGIN {
printf "{"
printf "\"Server\": \"" machine "\","
printf "\"Location\": \"" location "\","
printf "\"FileSystems\":["
}
{
if ($1 != "Filesystem") {
if (i) {
printf ","
}
printf "{\"mount\":\"" $6 "\",\"size\":\"" $2 "\",\"used\":\"" $3 \
"\",\"avail\":\"" $4 "\",\"use%\":\"" $5 "\",\"key\" :\"" (machine " " location " " $6) "\"}"
i++
}
}
END {
print "]}"
}
This converts the df input into JSON:
{
"Server": "Ubuntu 18.04 Test",
"Location": "4D-DC",
"FileSystems": [{
"mount": "/dev",
"size": "1988700",
"used": "0",
"avail": "1988700",
"use%": "0%",
"key": "Ubuntu 18.04 Test 4D-DC /dev"
}, {
"mount": "/run",
"size": "403972",
"used": "1092",
"avail": "402880",
"use%": "1%",
"key": "Ubuntu 18.04 Test 4D-DC /run"
}, {
"mount": "/",
"size": "32893712",
"used": "17614104",
"avail": "13585656",
"use%": "57%",
"key": "Ubuntu 18.04 Test 4D-DC /"
}, {
"mount": "/dev/shm",
"size": "2019852",
"used": "0",
"avail": "2019852",
"use%": "0%",
"key": "Ubuntu 18.04 Test 4D-DC /dev/shm"
}, {
"mount": "/run/lock",
"size": "5120",
"used": "0",
"avail": "5120",
"use%": "0%",
"key": "Ubuntu 18.04 Test 4D-DC /run/lock"
}, {
"mount": "/sys/fs/cgroup",
"size": "2019852",
"used": "0",
"avail": "2019852",
"use%": "0%",
"key": "Ubuntu 18.04 Test 4D-DC /sys/fs/cgroup"
}, {
"mount": "/u",
"size": "263174148",
"used": "61536",
"avail": "249690892",
"use%": "1%",
"key": "Ubuntu 18.04 Test 4D-DC /u"
}, {
"mount": "/run/user/1000",
"size": "403968",
"used": "0",
"avail": "403968",
"use%": "0%",
"key": "Ubuntu 18.04 Test 4D-DC /run/user/1000"
}]
}
Now that the format of the df output was in JSON format, I wanted to put it all the data into an Excel Spreadsheet, which I could easily keep up to date with a cron job.
Consume the JSON with a HTTP request in Microsoft Flow
The next step was to consume the data into Microsoft Flow. I created a simple four step flow:
- Consume the JSON with a simple HTTP Post:

- Update Existing Rows in the Spreadsheet:
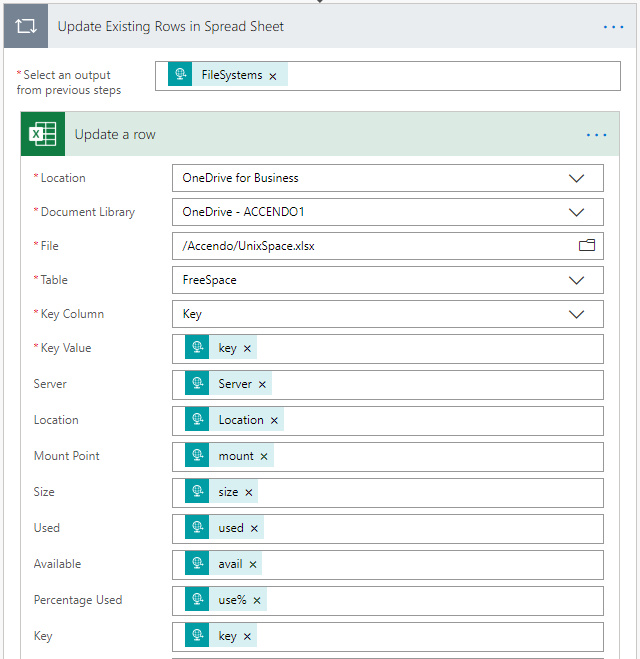
- If step two failed (i.e) no matching row existed, then add new rows:

- Terminate the flow:

This all works really well, I tested it on IBM AIX, Sco Openserver 5 and various versions of Ubuntu, all worked without a problem.
Putting it all together
There is some detail missing from the above, so I am going to paste all of the code here so that if you want to replicate the functionality you can do so easily:
freeSpaceFlow.sh
This shell script it what puts everything together, run it like this:
./freeSpaceFlow.sh machineName Location
This is the code
#!/bin/sh
df -P -k | \
grep -v "/snap/core" | \
/usr/bin/awk -v machine="$1" -v location="$2" -f ./freespace.awk | \
curl -X POST \
"https://prod-82.westeurope.logic.azure.com:443/workflows/...." \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d @-
It’s fairly simple to see what it does, but I will quickly explain:
- Runs the df command and pipes the output to grep.
- Uses grep to remove unwanted filesystems and pipes to awk.
- awk runs “freespace.awk” and creates json and pipes to curl.
- curl consumes stdin of the awk script for the payload to posts the data to Microsoft Flow.
Lets’ see the flow in action:

The Excel document is just a simple table with some formulas to convert the values to Gigabytes.
It feels great to bring data in from Unix with curl over to Excel via flow, it seems to be really reliable too.
Leave a Reply