This post explains how to extract text from Microsoft Word docx files using only built in actions in Power Automate. 3rd party actions exist, which are more probably more sophisticated and can certainly make this process easier.
This flow gets complex quickly!
But there is an easier way! Check out Power Tools for Power Automate which can extract text from a Word Document in a Single Action.
So please continue to read this post if you have lots of free time! Otherwise check out the amazing functionality of Power Tools for Power Automate
docx files are actually zip files
The first thing to that is important to understand, is that a word docx file is actually a zip file that contains a number of folders and files. The root of the zip folder contains these files:
The word folder in the root of the zip file contains more files and folders:

Within the word folder, there is a file called document.xml (sometimes documentN.xml) which contains the actual document content, and this is the file which we will parse with Power Automate. My example word document looks like this:

The content of document.xml contains:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" mc:Ignorable="w14 w15 wp14">
<w:body>
<w:p xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordml" w:rsidP="65D7FFCD" w14:paraId="2C078E63" wp14:textId="568EF955">
<w:pPr>
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
</w:pPr>
<w:bookmarkStart w:name="_GoBack" w:id="0"/>
<w:bookmarkEnd w:id="0"/>
<w:r w:rsidRPr="65D7FFCD" w:rsidR="648E6FBB">
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
<w:t xml:space="preserve">How to extract </w:t>
</w:r>
<w:r w:rsidRPr="65D7FFCD" w:rsidR="648E6FBB">
<w:rPr>
<w:b w:val="1"/>
<w:bCs w:val="1"/>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
<w:t xml:space="preserve">text </w:t>
</w:r>
<w:r w:rsidRPr="65D7FFCD" w:rsidR="648E6FBB">
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
<w:t>from a Microsoft Word docx file</w:t>
</w:r>
<w:r w:rsidRPr="65D7FFCD" w:rsidR="4ECA4038">
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
<w:t>.</w:t>
</w:r>
</w:p>
<w:p w:rsidR="65D7FFCD" w:rsidP="65D7FFCD" w:rsidRDefault="65D7FFCD" w14:paraId="77484B81" w14:textId="049555E8">
<w:pPr>
<w:pStyle w:val="Normal"/>
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
</w:pPr>
</w:p>
<w:p w:rsidR="4ECA4038" w:rsidP="65D7FFCD" w:rsidRDefault="4ECA4038" w14:paraId="10A0E5FC" w14:textId="67D59CCA">
<w:pPr>
<w:pStyle w:val="Normal"/>
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
</w:pPr>
<w:r w:rsidRPr="65D7FFCD" w:rsidR="4ECA4038">
<w:rPr>
<w:sz w:val="24"/>
<w:szCs w:val="24"/>
</w:rPr>
<w:t>This document explains how to extract text from a Microsoft Word document using standard Power Automate actions. The result isn’t perfect, but it should be good enough for basic usage.</w:t>
</w:r>
</w:p>
<w:sectPr>
<w:pgSz w:w="12240" w:h="15840" w:orient="portrait"/>
<w:pgMar w:top="1440" w:right="1440" w:bottom="1440" w:left="1440" w:header="720" w:footer="720" w:gutter="0"/>
<w:cols w:space="720"/>
<w:docGrid w:linePitch="360"/>
</w:sectPr>
</w:body>
</w:document>
As you can see from the above, the text data is on lines 18,27,34, 41 and 66 of the XML file.
Step 1 – Extract the contents of the Word document
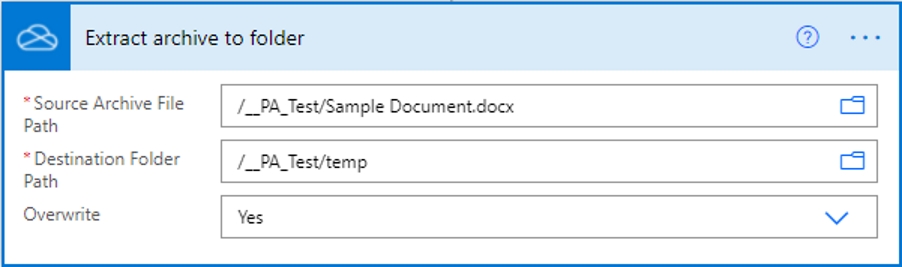
To be able to access the content of document.xml the docx file needs to be extracted first. Use the flow action Extract archive to folder to extract the docx file to a temporary folder. Make sure you set the overwrite option to Yes.
Note: You will not be able to select the word document from the file browser within the action because it filters the available files to show only files with a .zip extension. So you can either:
- Rename the docx file to .zip
- Put in the file path manually or use dynamic content from a previous step
In my flow, the action looks like this:
Step 2 – Filter the output of the extraction
The output of the Extract archive to folder action is an array of objects which contains information about every file extracted from the archive. This output needs to be filtered so that we can get the file Id of the document.xml. So add a filter array action and use the output of Extract archive to folder as the input for the filter. Click the edit in advanced mode link and use this filter expression:
@and(startsWith(item()['Name'], 'document'),endsWith(item()['Name'], 'xml'))
This will filter the array and narrow it down to just the file containing the document contents. Here is how my filter array looks:

Step 3 – Get the file content of document.xml
Add a Get file content action and use this expression for the file:
first(body('Filter_array'))['Id']
It should look like this:

Step 4 – Grab the content of the text elements
Finally, add a compose action and use the following expresison:
xpath(xml(outputs('Get_file_content')?['body']), '//*[name()=''w:t'']/text()')
Here is how it looks in my flow:

The xpath expression will grab each element named w:t and return an array of strings of the content found in those elements. Click here If you’d like to learn more about the structure of a word docx file. The output from my sample document produced the following array:
[ "How to extract ", "text ", "from a Microsoft Word docx file", ".", "This document explains how to extract text from a Microsoft Word document using standard Power Automate actions. The result isn’t perfect, but it should be good enough for basic usage." ]
At this point you can either iterate through the results, or use a simple join expression to create a single string from the results. Here is a screenshot of the entire flow:
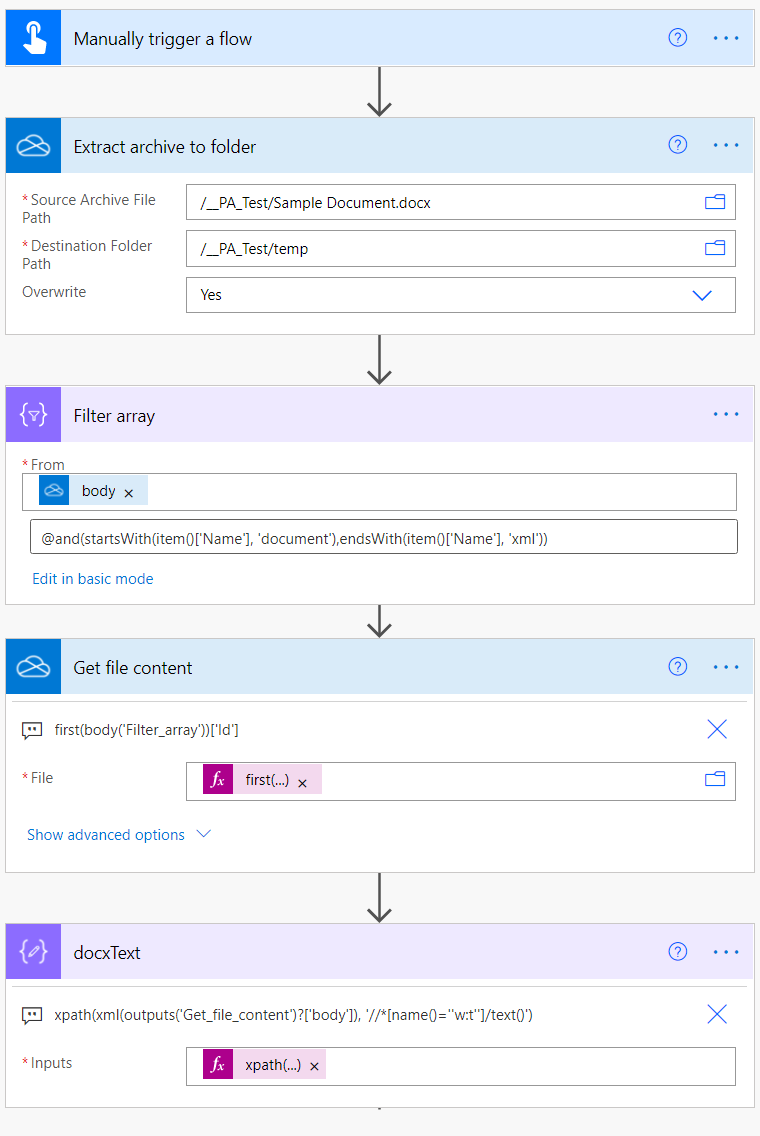
As you can see from the above, it is possible to Extract Text from a Word docx file with Power Automate quite easily, and a more sophisticated xpath expression could target specific regions of text required.
erfan says
Is the process similar if I would like to read the content and some particular textfield from an HTML file?
ARUN says
Hi Paulie,
could you please provide xpath lines to extract paragraph properties, paragraph Id, Text Font styles?
Rune Holm says
G R E A T! Works like a charm 😉
Bradley Brooks says
Instead of extracting text, how can I replace text (specifically a place holder in a template doc) and then re-zip it?
Micah says
@Bradley Brooks – I’m not certain on how to re-zip, but I’ve used the “replace” expression a few times and it has worked well.
Below is what I used to remove the [] and ” from the extracted text by using the “Compose” action. It would be added after the docxText action.
replace(replace(replace(string(outputs(‘docxText’)), ‘[‘, ”), ‘]’, ”), ‘”‘, ”)
Mark says
Hi
I am wondering if the following would be possible?
1. Ctrl + H (find and replace one word with another)
2. Open a folder of Word Docs (saved somewhere like OneDrive as needed)
3. Go through each document in the folder and carry out the specific Ctrl + H command
4. Overwrite the old Word docs with the new ones in the folder
The documents in the folder will change each time, but the folder location can remain constant.
The word being replaced in the Ctrl + H (Microsoft Word shortcut) function will change everytime.
Thanks
mac says
Thank you!! Been looking everywhere for this solution and yours is so easy to follow
David F says
This works great, thanks! How would I add to the xpath expression to include the Heading format information as well as the document text?
e.g.
I’d want to get the Heading3 value to output to the array also.
I need to capture when each document section starts and ends.
Bob says
This works great with a local word document. But is there a way to do this with a word document on sharepoint?
When I try it with a sharepoint document i get:
The template language expression ‘first(body(‘filter_array’))[‘Id’]’ cannot be evaluated because property ‘Id’ cannot be selected.
GED says
how to put it in csv, without distorting the new lines
AM says
Is there a equivalent SharePoint API call to perform same operation using HTTP Action?
AM says
Is there a equivalent SharePoint API call to perform same operation using HTTP Action instead of using Extract Folder action?
Alex Rackwitz says
Encodian’s connector just released an action to extract text from Word for a simple no code 1 action solution:
https://support.encodian.com/hc/en-gb/articles/10583756977180-Get-Text-from-Word
Zaria says
Encodian’s connector just released an action to extract text from Word for a simple no code 1 action solution:
https://support.encodian.com/hc/en-gb/articles/10583756977180-Get-Text-from-Word
this crap costs money, we want free
Johnny Zraiby says
Hello.
When I extract to Folder, and use Filter Array after that, it returns no result. I noticed that the document.xml file is in a folder called word inside the extracted folder.
How can I modify the Filter Array to get the document.xml file?
Rob says
SharePoint is a little trickier. The Extract Folder action only lists folders.
You need to do these steps:
0 – Extract the file as above
1 – filter the array to the “word” folder and grab the id – @equals(@{item()[‘Name’]},’word’)
2 – Use the List Folder action to get the files array using that id – first(body(‘Filter_array’))[‘Id’]
3 – filter that array to get the id of the file you want – @equals(@{item()[‘Name’]},’comments.xml’) Note I want comments not the text
4 – get file content using the ID from 3